
Que veut dire GPT dans ChatGPT ? Signification

Ce qu’il faut retenir : l’acronyme GPT (Generative Pre-trained Transformer) désigne un modèle capable de générer du texte nouveau en prédisant la suite logique des mots. Il ne s’agit pas d’une conscience, mais d’un système statistique nourri par une immense bibliothèque numérique. C’est la technologie moteur qui alimente ChatGPT, transformant des milliards de données en conversations fluides.
Vous sollicitez cette intelligence artificielle quotidiennement, mais savez-vous exactement que veut dire gpt dans chatgpt ou utilisez-vous cet acronyme par simple mimétisme ? Il ne s’agit pas juste d’un nom de code marketing, mais de la description précise du moteur sous le capot : un transformateur génératif pré-entraîné capable de véritables prouesses linguistiques. Loin des cours magistraux soporifiques, nous allons voir comment ces trois concepts techniques s’assemblent pour donner vie à l’outil qui a changé nos habitudes de travail.
GPT décodé : la signification brute derrière l’acronyme
GPT signifie Generative Pre-trained Transformer. C’est l’architecture d’apprentissage profond qui permet à ChatGPT de comprendre vos demandes et de formuler des réponses en langage naturel, une technologie que beaucoup utilisent quotidiennement sans en saisir la mécanique sous-jacente.
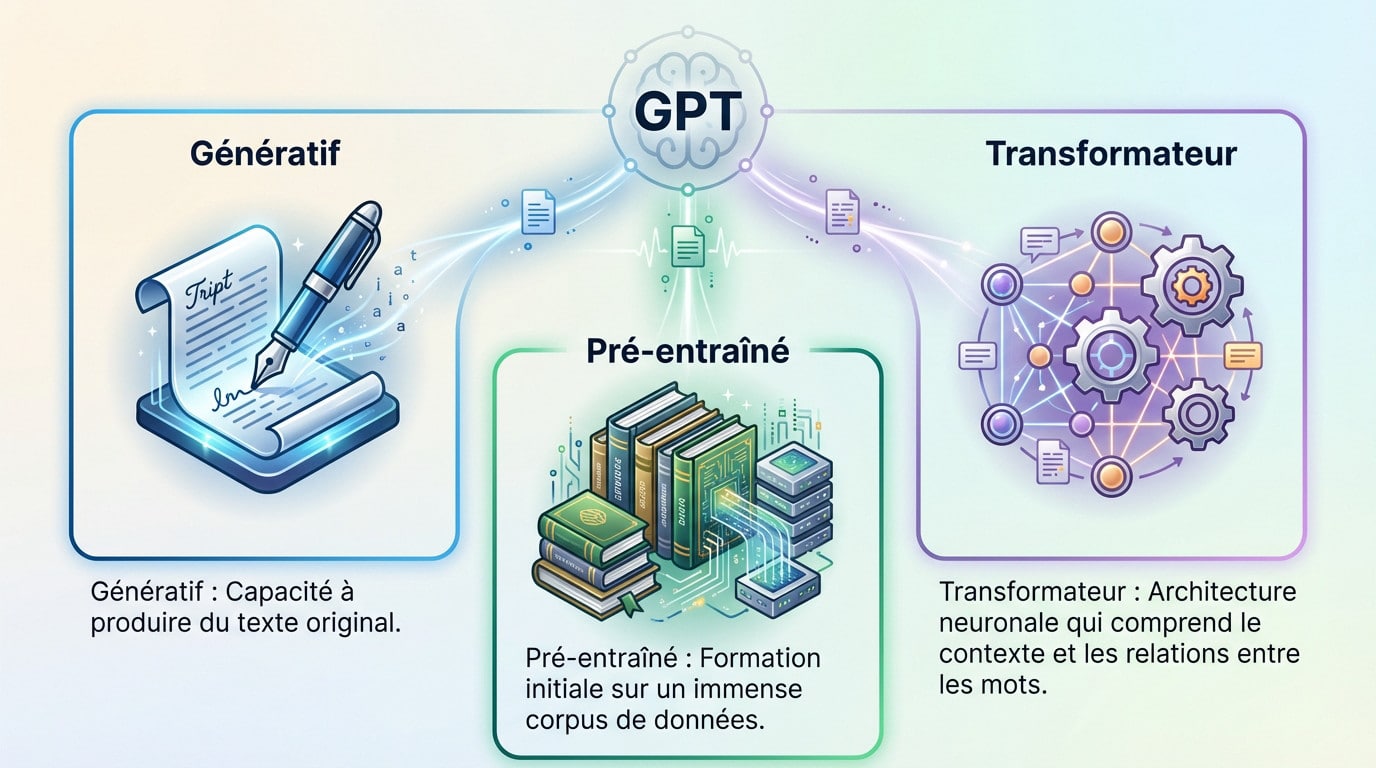
G comme génératif : la capacité de créer
Le terme “Génératif” indique que le modèle ne se borne pas à répéter des informations existantes, il crée du texte nouveau. Sa fonction première consiste à produire du contenu inédit en réponse à une demande précise, le fameux prompt.
Voyez cela comme un musicien de jazz qui improvise une nouvelle mélodie à partir d’accords connus, plutôt qu’un simple lecteur qui déchiffre une partition. Il compose en temps réel.
Cette faculté de génération unique est exactement ce qui rend les réponses de ChatGPT si fluides et humaines.
P comme pré-entraîné : le savoir accumulé
La notion de “Pré-entraîné” signifie que le modèle a été formé sur une quantité colossale de données textuelles AVANT d’être spécialisé pour la conversation. C’est sa phase d’apprentissage fondamentale, un gavage intensif d’informations pour bâtir sa logique.
Il a ingéré une bibliothèque numérique gigantesque : des millions de livres, l’intégralité de Wikipédia, des articles de presse et même du code informatique. C’est son socle de connaissances.
Ce pré-entraînement massif lui confère une compréhension générale du monde et de ses nuances. Il maîtrise ainsi la grammaire, les concepts abstraits et les différents styles d’écriture.
T comme transformateur : l’architecture qui change tout
Le “Transformateur” constitue le moteur technique caché sous le capot de GPT. C’est une architecture de réseau neuronal spécifique, conçue pour gérer les subtilités du langage humain.
Son rôle principal est simple mais puissant : il permet au modèle de peser l’importance de chaque mot dans une phrase pour comprendre le contexte global. C’est le mécanisme d’attention qui relie les concepts entre eux.
C’est cette architecture précise qui permet à ChatGPT de suivre des conversations longues et de générer des réponses cohérentes et contextuelles sans perdre le fil.
- Génératif : Capacité à produire du texte original.
- Pré-entraîné : Formation initiale sur un immense corpus de données.
- Transformateur : Architecture neuronale qui comprend le contexte et les relations entre les mots.
Le concept de génération : comment ChatGPT crée-t-il vraiment du texte ?
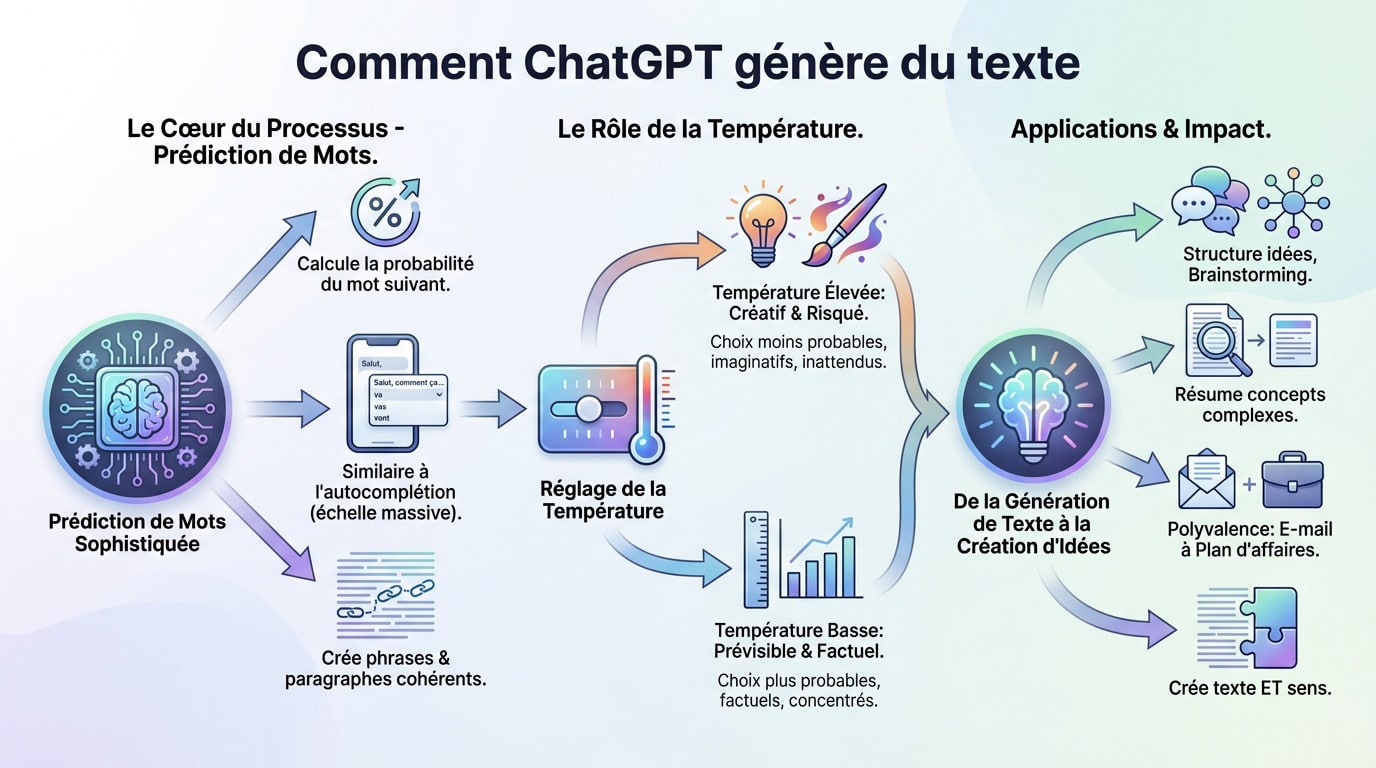
Plus qu’une simple répétition : la prédiction de mots
Soyons honnêtes : ChatGPT ne « pense » pas. Il opère fondamentalement comme un prédicteur de mots ultra-sophistiqué, sans conscience réelle. À chaque étape du processus, l’algorithme évalue et calcule la probabilité statistique exacte du mot suivant le plus logique dans la séquence.
Voyez cela comme la fonction d’autocomplétion de votre smartphone, mais à une échelle monumentale. La complexité ici est des milliards de fois supérieure à celle de votre clavier habituel, traitant des contextes immenses.
Le génie du système, c’est que cette prédiction en chaîne finit par former des phrases et des paragraphes cohérents.
Le rôle de la “température” : entre créativité et prévisibilité
Abordons le concept de « température », un réglage technique qui influence radicalement la génération. Ce n’est pas un terme grand public, mais il est au cœur du processus pour moduler les réponses.
Une température basse rend les réponses très prévisibles et factuelles, sans aucune surprise. À l’inverse, une température élevée pousse le modèle à prendre des risques, choisissant des mots moins probables pour stimuler la créativité, quitte à commettre parfois des erreurs grossières.
OpenAI a trouvé un équilibre précaire pour que ChatGPT reste utile tout en étant capable d’une certaine originalité.
De la génération de texte à la création d’idées
Cette capacité de génération dépasse largement la simple écriture mécanique. Elle permet de structurer des idées complexes, de lancer un brainstorming efficace ou de résumer des concepts ardus. L’outil ne fait pas que rédiger, il organise la pensée pour vous.
C’est précisément ce qui explique pourquoi on l’utilise pour tout, de la rédaction d’un e-mail rapide à l’ébauche complète d’un plan d’affaires solide.
Cette polyvalence est une conséquence directe de la puissance du modèle génératif actuel. Il assemble des mots pour créer non seulement du texte lisible, mais aussi du sens véritable.
Le pré-entraînement : la construction d’une “bibliothèque mentale” numérique
Un appétit gargantuesque pour les données
Le pré-entraînement implique de “nourrir” le modèle avec des centaines de milliards de mots. C’est une ingestion massive de données, l’équivalent numérique de lire des bibliothèques entières en un instant.
Ces données proviennent d’une version filtrée d’Internet, incluant le vaste corpus Common Crawl. Cela englobe des corpus de livres, l’intégralité de Wikipédia, des articles de presse, des blogs et des forums de discussion.
L’objectif est d’exposer le modèle à la quasi-totalité des connaissances humaines écrites et numérisées disponibles.
Apprendre sans supervision : la magie de l’auto-apprentissage
Cette phase est dite “non supervisée”, ce qui change la donne. Personne ne dit au modèle “ceci est une bonne phrase, cela est une mauvaise phrase”. Il apprend par lui-même en observant les structures.
La technique est simple en principe : on lui donne un texte avec des mots masqués et son seul but est de deviner les mots manquants.
En répétant cet exercice des milliards de fois, il finit par intérioriser les règles de grammaire, la syntaxe, les faits et même les styles d’écriture.
Les limites et les biais de la connaissance pré-entraînée
Mais le modèle apprend tout en bloc, le bon comme le mauvais. Il hérite inévitablement des biais, stéréotypes et informations erronées présents dans ses données d’entraînement massives.
Il faut noter la “coupure de connaissance“, qui piège souvent les utilisateurs. Le modèle ne connaît rien des événements survenus après la fin de son entraînement. C’est pourquoi il peut être dépassé sur l’actualité récente.
C’est une limite fondamentale à garder en tête lorsqu’on utilise ChatGPT au quotidien.
- Livres numérisés : Des millions de titres pour la structure narrative et le vocabulaire.
- Wikipédia : Une base de connaissances factuelles structurée.
- Articles de presse et blogs : Pour le style d’écriture contemporain et l’information générale.
- Conversations en ligne (filtrées) : Pour apprendre le ton conversationnel et les interactions humaines.
Le transformateur : le secret de la compréhension du contexte
Avoir une immense base de connaissances ne sert à rien si on ne peut pas l’utiliser intelligemment. C’est exactement là qu’intervient l’architecture Transformer, la véritable pièce maîtresse qui permet à GPT de structurer sa pensée.
Avant le transformateur : la mémoire courte des IA
Avant cette rupture technologique, nous utilisions principalement des Réseaux de Neurones Récurrents (RNN) qui traitaient l’information de manière laborieuse. Ces anciens modèles lisaient les phrases mot après mot, de façon linéaire, et finissaient souvent par “oublier” le début du texte avant même d’arriver au point final.
Le résultat était souvent frustrant : les textes générés perdaient rapidement toute cohérence logique. Le contexte s’évaporait en cours de route, rendant impossible la tenue d’un propos structuré sur la longueur.
C’était un obstacle technique majeur qui empêchait toute forme de compréhension réelle du langage naturel par une machine.
Le mécanisme d’attention : la clé pour comprendre le contexte
Tout a changé lorsque l’architecture Transformer a introduit son innovation radicale : le “mécanisme d’attention”. Contrairement à ses prédécesseurs, cette approche ne lit pas bêtement de gauche à droite, mais analyse les relations entre les termes.
Imaginez votre propre lecture : vous ne donnez pas la même importance à chaque mot ; votre cerveau isole instantanément les termes clés pour saisir le sens global. Le Transformer opère de la même façon, mais via une approche mathématique rigoureuse.
Il observe l’ensemble de la phrase simultanément et décide quels mots sont pertinents pour éclairer le sens d’un terme précis. Cette vision globale change la donne.
Le mécanisme d’attention permet au modèle de peser l’influence de chaque mot sur les autres, peu importe leur distance, créant ainsi une compréhension profonde et nuancée du contexte global.
Pourquoi c’est si efficace pour la conversation
Dans un échange avec ChatGPT, le contexte est absolument tout. Si vous utilisez un pronom comme “il” ou “celui-ci”, cela peut faire référence à un sujet mentionné trois phrases plus tôt, ce qui perdait les anciennes IA.
Grâce à l’attention, le Transformer peut retrouver cette référence instantanément et comprendre de qui ou de quoi on parle. C’est cette capacité qui empêche la conversation de dérailler.
C’est ce mécanisme précis qui donne l’impression que l’IA possède une “mémoire” active durant votre discussion. Pour mieux comprendre le fonctionnement d’un chatbot actuel, il faut saisir que cette gestion du contexte est sa force principale.
L’impact du papier “Attention Is All You Need”
Cette technologie ne sort pas de nulle part : elle provient d’un article de recherche publié par Google en 2017, intitulé “Attention Is All You Need”. Ce papier a posé les fondations théoriques de tout ce que nous utilisons aujourd’hui.
Cet article a marqué un tournant historique dans la recherche en IA. Il a démontré qu’on obtenait des résultats bien supérieurs en abandonnant les anciennes méthodes pour se concentrer uniquement sur ces mécanismes d’attention.
C’est sur cette base solide qu’OpenAI a ensuite construit toute sa série de modèles GPT, exploitant cette architecture pour créer les outils que nous connaissons.
L’histoire de GPT : une évolution fulgurante
L’architecture Transformer a ouvert la voie, mais l’histoire de GPT est celle d’une course à la puissance et à la taille, chaque version repoussant les limites de la précédente.
Les débuts : GPT-1 et GPT-2
En 2018, GPT-1 débarque comme une simple preuve de concept. Avec ses 117 millions de paramètres, il démontre surtout que l’approche Transformer tient la route pour générer du texte cohérent.
Puis arrive GPT-2 en 2019, le premier modèle à vraiment secouer le cocotier. Ses résultats étaient si bluffants qu’OpenAI a refusé de le publier immédiatement, craignant une vague de désinformation massive et incontrôlable.
C’était le déclic. Le grand public commençait à entrevoir la puissance brute de ces algorithmes génératifs.
Le saut quantique : l’arrivée de GPT-3
Le vrai choc survient avec GPT-3 en 2020. On change totalement de dimension : ce monstre est plus de 100 fois plus massif que son prédécesseur, atteignant 175 milliards de paramètres.
Cette taille démesurée a fait surgir des capacités “émergentes”. Il pouvait réussir des tâches sans entraînement spécifique, simplement en analysant quelques exemples. On appelle ça le “few-shot learning”, et c’était inédit.
C’est ce modèle qui a brisé le plafond de verre, rendant possible les applications grand public et servant de fondation à la toute première mouture de ChatGPT.
Avec GPT-3, la simple augmentation de la taille du modèle et des données a débloqué des compétences inattendues, montrant que la quantité pouvait se transformer en qualité.
L’ère moderne : GPT-3.5 et GPT-4
GPT-3.5 n’est “que” une version affinée, optimisée pour le dialogue. Pourtant, c’est bien ce moteur qui a propulsé le lancement viral de ChatGPT en novembre 2022.
Aujourd’hui, GPT-4 (2023) domine les débats. Il ne se contente pas d’être plus gros ; il devient “multimodal”. Il analyse des images et possède un raisonnement logique bien plus affûté que ses aînés.
C’est la mécanique sous le capot de la version payante, offrant une précision et une nuance nettement supérieures.
GPT vs ChatGPT : le moteur et la voiture
On parle de GPT-3, GPT-4, ChatGPT… Il est facile de tout mélanger. Pourtant, la distinction est simple et fondamentale : l’un est le moteur, l’autre est le véhicule que nous conduisons tous les jours.
GPT : le modèle de langage fondamental
GPT, pour Generative Pre-trained Transformer, n’est pas le chatbot lui-même. C’est un modèle de langage brut, une architecture neuronale massive entraînée sur des milliards de données textuelles. Voyez-le comme un “cerveau” numérique accessible aux développeurs via une API.
Sa fonction première est purement statistique : il prédit le mot suivant. Si vous lui donnez un début de phrase, il la termine mécaniquement. Il n’est pas nativement conçu pour “discuter” ou suivre des instructions complexes, mais pour générer du texte.
ChatGPT : l’application conversationnelle affinée
À l’inverse, ChatGPT est une application spécifique construite par-dessus ce moteur. C’est l’interface grand public qui transforme la puissance brute de GPT en un outil utilisable.
Pour réussir ce tour de force, le modèle a été affiné pour la conversation. OpenAI a appliqué une méthode rigoureuse nommée RLHF (Reinforcement Learning from Human Feedback). Sans cela, l’IA resterait froide et imprévisible.
Concrètement, des humains ont noté des milliers de réponses pour lui apprendre à devenir un assistant utile, sûr et conversationnel. C’est ce qui rend notre avis détaillé sur ChatGPT si positif aujourd’hui.
Comparaison des versions : GPT-3.5 vs GPT-4 dans ChatGPT
Beaucoup ignorent que la vraie différence entre la version gratuite et payante réside dans le moteur sous le capot. C’est ce choix qui détermine la qualité de vos résultats.
L’offre gratuite tourne sur GPT-3.5, un modèle rapide mais limité, alors que l’abonnement “Plus” débloque GPT-4. Ce dernier est nettement plus performant sur la logique et la nuance.
Vous hésitez encore ? Le tableau suivant résume les différences concrètes qui changent l’expérience utilisateur.
| Caractéristique | GPT-3.5 (ChatGPT Gratuit) | GPT-4 (ChatGPT Plus) |
|---|---|---|
| Raisonnement complexe | Moyen, peut faire des erreurs logiques. | Excellent, bien meilleur pour les problèmes complexes. |
| Précision factuelle | Bonne, mais avec des “hallucinations” plus fréquentes. | Très élevée, moins sujet aux inventions. |
| Créativité et nuance | Bonne, mais parfois répétitif ou générique. | Supérieure, capable de styles plus complexes et nuancés. |
| Compréhension d’images (Multimodalité) | Non supporté (texte uniquement). | Supporté, peut analyser et décrire des images. |
| Limite de contexte | Plus courte (environ 3 000 mots). | Beaucoup plus longue (plus de 20 000 mots), meilleure mémoire de conversation. |
| Accès | Gratuit et largement accessible. | Payant, avec accès prioritaire et fonctionnalités avancées. |
GPT en action : comment votre prompt devient une réponse
Comprendre les composants, c’est bien. Mais voir comment ils s’articulent quand vous tapez une simple question dans la fenêtre de chat est encore plus éclairant.
De votre question à la “tokenisation”
La première étape est totalement invisible pour l’utilisateur lambda. Votre phrase n’est pas lue comme telle, mais instantanément découpée en petits morceaux numériques appelés “tokens”.
Un token n’est pas forcément un mot complet, loin de là. Ça peut être un mot entier, un fragment comme “généra-tif”, ou même juste un signe de ponctuation. C’est l’unité de base absolue que le modèle manipule pour travailler.
Cette décomposition chirurgicale permet au modèle de gérer n’importe quel texte, même face à des mots qu’il n’a jamais vus auparavant.
L’inférence : la recherche de la séquence la plus probable
Une fois la question “tokenisée”, le processus d’inférence s’enclenche immédiatement. C’est le moment critique où le modèle ne se contente plus de lire, mais “réfléchit” activement.
Le Transformer analyse les tokens de votre question, active les “neurones” pertinents dans son immense réseau, et calcule les probabilités pour la suite. Il ne devine pas ; il évalue statistiquement quel fragment a le plus de chances d’apparaître ensuite.
Il génère alors le token le plus probable, l’ajoute à la séquence existante, et recommence tout le processus en boucle jusqu’à générer un marqueur spécifique de “fin de texte”.
Le rôle du “fine-tuning” dans la qualité de la réponse
Attention, le modèle brut (pré-entraîné) ne donnerait pas forcément une bonne réponse. Il pourrait bêtement continuer votre question ou vous livrer une réponse factuelle mais totalement malpolie ou incohérente.
C’est là que l’affinage (fine-tuning) pour ChatGPT entre en jeu pour sauver la mise. Il a appris, via des retours humains, à suivre des instructions strictes et à se comporter comme un véritable assistant.
Cet affinage guide la génération pour qu’elle soit non seulement probable, mais aussi utile et appropriée pour découvrir ce qu’on peut faire avec ChatGPT.
Au-delà de ChatGPT : l’impact plus large de la technologie GPT
ChatGPT n’est que la partie la plus visible de l’iceberg. La technologie GPT est en train de s’infuser dans de nombreux autres domaines, bien au-delà de la simple conversation.
GPT comme moteur de créativité et de productivité
De nombreux outils intègrent désormais des modèles GPT. On le voit clairement dans les assistants d’écriture, les outils de résumé automatique ou les générateurs d’e-mails qui envahissent nos boîtes de réception.
Regardez le développement logiciel : des outils phares comme GitHub Copilot exploitent cette architecture pour suggérer des lignes de code entières. C’est un gain de temps massif qui transforme radicalement le quotidien des programmeurs.
Bref, GPT s’impose comme un véritable partenaire de travail quotidien pour une multitude de professions.
La génération d’images, de musique et au-delà
L’architecture Transformer ne se limite pas aux mots. Des modèles comme DALL-E, aussi signés OpenAI, appliquent ces principes pour générer des images à partir de descriptions textuelles. C’est la même mécanique sous le capot.
Cette logique s’applique aussi à la musique ou la vidéo. Le “G” de GPT s’étend désormais à tous les types de médias, brisant les frontières créatives.
On voit émerger des outils capables de créer des bandes sonores, basés sur ces fondations. D’ailleurs, les générateurs d’images par IA ne sont que le début de cette vague créative.
Les défis et l’avenir des modèles GPT
Il faut parler des défis : la consommation énergétique massive, les risques de désinformation à grande échelle et la question épineuse des droits d’auteur sur les données d’entraînement.
L’avenir appartient probablement à des modèles plus petits et spécialisés. Les chercheurs travaillent d’arrache-pied pour améliorer leur fiabilité et réduire leurs biais, rendant ces outils plus sûrs pour tous.
La course à l’IA générale est lancée, et les modèles GPT en sont une étape majeure.
- Assistance au codage : Suggestion et écriture de code informatique (ex: GitHub Copilot).
- Recherche scientifique : Analyse et résumé d’articles de recherche, formulation d’hypothèses.
- Création de contenu marketing : Rédaction de slogans, d’articles de blog ou de posts pour les réseaux sociaux.
- Éducation personnalisée : Création de tuteurs virtuels qui s’adaptent au niveau de l’élève.
Les implications éthiques et les limites de GPT
Une technologie aussi puissante ne vient pas sans son lot de questions et de responsabilités. Comprendre ce que veut dire GPT, c’est aussi comprendre ses zones d’ombre.
Le problème persistant des “hallucinations”
Vous avez peut-être déjà remarqué ce phénomène étrange : le modèle invente des faits, des sources ou des citations avec une assurance déconcertante. C’est sans doute l’un de ses défauts les plus traîtres.
Ce n’est pas de la malice, c’est purement mathématique. Comme il fonctionne en prédisant le mot suivant, s’il lui manque l’information exacte, il génère la séquence la plus plausible statistiquement, même si le résultat est factuellement faux.
La vérification humaine reste donc absolument indispensable pour toute information critique générée par GPT.
Biais et reproduction des stéréotypes
N’oubliez jamais que le modèle apprend en ingérant des milliards de textes humains. Par conséquent, il a assimilé et peut reproduire nos propres biais sociaux et culturels sans le moindre filtre moral.
Prenons un cas concret et inquiétant. Si les données d’entraînement associent majoritairement le mot “infirmière” aux femmes et “ingénieur” aux hommes, l’algorithme risque fort de renforcer ce stéréotype sexiste dans ses réponses.
Bien qu’OpenAI travaille activement pour atténuer ces dérives, c’est un combat permanent et complexe. Au fond, l’IA agit comme un miroir de nos propres sociétés.
La question de l’originalité et de la détection
Le texte généré est-il vraiment “original” ? La question est autant juridique que philosophique. Techniquement, il s’agit surtout d’une recombinaison sophistiquée de tout ce que la machine a appris auparavant.
Cela crée un véritable casse-tête, notamment dans le journalisme ou l’éducation. Si les outils pour détecter un texte de ChatGPT existent bel et bien, leur fiabilité fait souvent débat face à des modèles qui s’humanisent.
La frontière […] triche pure devient de plus en plus floue.
Finalement, derrière l’acronyme un peu barbare de Generative Pre-trained Transformer se cache une technologie qui redéfinit notre rapport à l’écrit. GPT n’est pas de la magie, mais une prouesse mathématique fascinante. Maintenant que vous avez soulevé le capot du moteur, vous ne regarderez plus jamais ce curseur clignoter de la même façon
FAQ
Que signifie exactement l’acronyme GPT ?
L’acronyme GPT tient pour Generative Pre-trained Transformer. Si on le traduit mot à mot, cela donne “Transformateur Génératif Pré-entraîné”. Derrière ce jargon technique se cachent trois concepts clés : il est “Génératif” car il crée du texte inédit, “Pré-entraîné” car il a lu une immense partie d’Internet pour apprendre avant de vous parler, et “Transformer” désigne son architecture neuronale révolutionnaire.
Pourquoi retrouve-t-on “GPT” dans le nom ChatGPT ?
C’est un peu comme demander pourquoi il y a “V8” dans le nom d’un moteur de voiture. GPT est le moteur technologique qui fait tourner la machine. ChatGPT n’est “que” l’interface de discussion (le Chat) qui rend cette technologie accessible et conviviale. Sans le modèle GPT en coulisses, ChatGPT ne serait qu’une coquille vide incapable de comprendre votre demande.
Qui a inventé la technologie GPT ?
C’est l’organisation de recherche en intelligence artificielle OpenAI qui a développé et popularisé la série des modèles GPT (de GPT-1 en 2018 jusqu’à GPT-4 et au-delà). Cependant, il faut rendre à César ce qui est à César : l’architecture “Transformer”, qui est la brique fondamentale de cette technologie, a été initialement inventée et publiée par des chercheurs de Google en 2017.
Comment pourrait-on traduire ChatGPT en français ?
Une traduction littérale donnerait quelque chose comme “Transformateur Génératif Pré-entraîné de Discussion”. C’est assez indigeste, n’est-ce pas ? C’est précisément pour cette raison que l’acronyme anglais s’est imposé partout. Il décrit un robot conversationnel capable de générer du texte de manière autonome grâce à une immense base de connaissances digérée au préalable.



