
Wikipedia fait maintenant payer les IA et met fin au pillage de ses données

Ce qu’il faut retenir : pour stopper le pillage de ses serveurs, Wikipédia facture désormais l’accès aux données pour les IA. Ce pivot assure la pérennité financière face aux géants de la tech. Comble de l’ironie, l’encyclopédie vend son contenu aux robots mais interdit strictement à ses bénévoles d’utiliser ces mêmes outils pour rédiger.
Saviez-vous que les IA génératives siphonnent le savoir mondial sans verser un centime, mettant ainsi en péril l’infrastructure technique et la survie économique de notre chère encyclopédie libre ? Face à ce constat alarmant, la fondation contre-attaque avec le projet wikipedia facturation ia, une mesure ferme obligeant enfin les géants de la tech à rémunérer l’usage intensif de leurs robots gloutons. Nous détaillons ici les enjeux de cette riposte financière inédite qui bouleverse désormais les règles du jeu entre le partage bénévole et l’appétit insatiable des algorithmes commerciaux.
Le pillage des données : Wikipédia siffle la fin de la récré
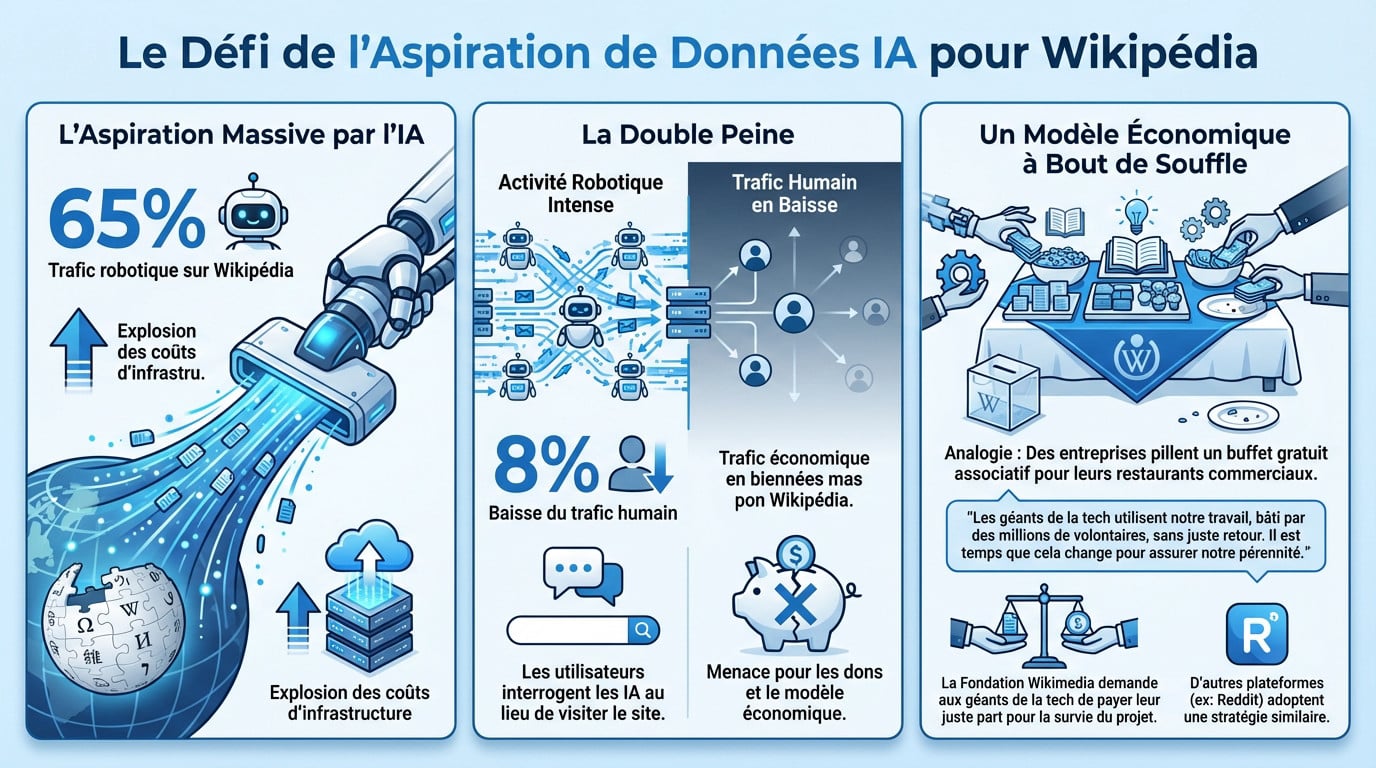
La double peine : des serveurs qui fument et des visiteurs qui désertent
Les robots des IA aspirent le contenu de Wikipédia avec une frénésie inquiétante. Ce pillage numérique est devenu insoutenable pour l’organisation. En effet, ce trafic robotique représente désormais 65 % du trafic total. Résultat, le coût d’infrastructure de la fondation explose littéralement.
La conséquence de ce siphonnage est brutale : une baisse de 8 % du trafic humain. Les internautes ne cliquent plus sur les liens. Ils interrogent directement les IA, pourtant nourries à la source Wikipédia.
Ce changement de comportement menace directement le modèle économique. Moins de visiteurs humains signifie mécaniquement moins de dons pour tenir l’édifice.
Un modèle économique à bout de souffle
Imaginez une association offrant un buffet gratuit pillé par des restaurants commerciaux. Ces entreprises revendent ensuite les plats sans rien laisser aux autres. C’est exactement ce que subit Wikipédia aujourd’hui.
La Fondation Wikimedia ne veut pas fermer l’accès, mais exige que les géants de la tech paient leur part. C’est une question de survie. La wikipedia facturation ia devient inévitable pour garantir l’avenir.
Les géants de la tech utilisent notre travail, bâti par des millions de volontaires, sans juste retour. Il est temps que cela change pour assurer notre pérennité.
Reddit a d’ailleurs adopté une stratégie similaire pour protéger ses acquis. C’est vital pour maîtriser les coûts de l’IA.
Wikimedia Enterprise : la voie royale (et payante) pour les IA
Face à cette situation, quelle solution ? Pas une interdiction, mais une nouvelle porte d’entrée formelle et tarifée.
Plus qu’un simple accès : une API pensée pour les pros
Voici Wikimedia Enterprise, l’offre commerciale conçue pour les besoins massifs des IA. C’est une API payante, robuste et taillée pour le business.
Son but est simple : fournir des données propres via des flux structurés et des mises à jour en temps réel.
Ce service offre des avantages que le scraping n’égalera jamais :
- Qualité des données : un flux filtré, sans les déchets du scraping.
- Haute disponibilité : des garanties contractuelles (SLA) solides.
- Cadre légal : une licence sécurisant enfin l’usage commercial.
- Attribution : des mécanismes pour citer correctement la source.
La fin du “tout gratuit” pour les géants de la tech
Fini la zone grise. Avec cette wikipedia facturation ia, les coûts deviennent enfin prévisibles pour les entreprises.
Rassurez-vous, un palier gratuit subsiste pour l’exploration. La facturation cible l’usage commercial intensif, basé sur la quantité de données exportées.
Voyez la différence pour vos plateformes d’agents conversationnels IA entre le bricolage et la solution pro :
| Caractéristique | Scraping “sauvage” | API Wikimedia Enterprise |
|---|---|---|
| Coût | Caché (Wiki paie) | Direct (licence) |
| Fiabilité | Faible (instable) | Élevée (SLA) |
| Légalité | Zone grise | Claire (contrat) |
| Qualité | Brute, non structurée | Propre, structurée |
| Idéal pour | Petits projets | Entreprises d’IA |
Une question de survie et d’éthique pour l’encyclopédie
L’IA, ce vampire de connaissance qui ne cite pas ses sources
Les IA génératives doivent une grande partie de leur savoir à Wikipédia. Face au pillage, la facturation Wikipedia IA devient une nécessité vitale. C’est leur carburant factuel, une base de données colossale vérifiée par des humains. Sans nous, leur fiabilité s’effondrerait.
Le problème est purement éthique. Ces modèles absorbent l’info et la recrachent sans jamais citer la source principale, s’attribuant le mérite du travail de millions de bénévoles.
Si les IA continuent de présenter nos contenus comme les leurs, pourquoi les gens viendraient-ils encore sur notre site ou feraient-ils des dons pour nous soutenir ?
L’accord avec Google : un précédent qui fait jurisprudence ?
Cette démarche n’est pas une nouveauté radicale. Un accord commercial existe déjà avec Google, qui utilise Wikimedia Enterprise pour son Knowledge Graph. C’était la première pierre de l’édifice.
Cet accord a servi de preuve de concept éclatante. Il démontre qu’une collaboration équitable avec les géants du web est possible et surtout bénéfique pour la fondation.
L’objectif final est d’étendre ce modèle à tous les grands acteurs de l’IA. Des négociations sont en cours pour que d’autres entreprises rejoignent le mouvement. Elles doivent participer à la pérennité de la connaissance libre.
Le double discours : Wikipédia face à l’IA en interne
Alors que le dossier wikipedia facturation ia avance pour faire payer les géants de la tech, une autre bataille se joue : comment les contributeurs doivent-ils utiliser ces outils ?
“N’utilisez pas l’IA” : la consigne stricte aux contributeurs
La Fondation Wikimedia déconseille vivement l’usage d’IA génératives pour la rédaction. Le risque d’erreurs factuelles, d’hallucinations ou de plagiat est simplement trop élevé pour être ignoré.
Cela heurte de plein fouet l’ADN de l’encyclopédie : la fiabilité et la vérifiabilité des sources. Une IA ne garantit rien de tout ça.
Ne vous y trompez pas : vous restez l’unique responsable légal et éditorial de vos ajouts. C’est vous qui portez le chapeau, pas le robot.
Des exceptions tolérées, mais sous haute surveillance
Ce n’est pas une interdiction totale, mais ne sortez pas le champagne. Certains usages sont tolérés, à condition de respecter un encadrement draconien.
Voici les règles du jeu :
- Transparence obligatoire : Vous devez déclarer l’usage d’une IA dans le résumé.
- Vérification humaine : Un expert doit impérativement contrôler chaque mot généré.
- Usages limités : Seulement pour reformuler, corriger ou résumer une source lue.
- Sanctions prévues : Un abus mène directement au blocage du compte.
C’est assez ironique : Wikipédia vend ses données aux IA, mais bride ses propres équipes. La méfiance règne. Pour vérifier vos textes, testez ces détecteurs IA gratuits.
Wikipédia siffle la fin de la récré pour les IA. Avec Wikimedia Enterprise, l’encyclopédie force la tech à passer à la caisse pour sauver le savoir libre. Un paradoxe savoureux : nourrir les robots pour payer les factures, tout en interdisant aux rédacteurs de s’en servir. L’humain garde le dernier mot… pour l’instant !



