
RAG chatbot : quand l’IA se souvient enfin
Pour aller à l’essentiel : Le RAG chatbot transforme un LLM en Sherlock Holmes des données, combinant sa puissance de génération avec un accès instantané à des sources fraîches. Résultat ? 75% de hallucinations en moins et des réponses sourcées, comme un étudiant consciencieux qui cite ses manuels. L’IA devient un allié fiable, idéal pour qui veut éviter les délires d’un robot bloqué en 2020.
Vous avez déjà demandé à un chatbot si les dinosaures existent encore et reçu une réponse sur leur club de gym ? Le drame des LLM classiques, c’est leur mémoire d’éléphant… sauf que l’éléphant a arrêté les actualités en 2021. Le rag chatbot, lui, c’est le bibliophile accro aux mises à jour : il va chercher l’info en temps réel, évite de vous raconter que la Terre est plate, et vous citera même sa source. Dans cet article, on vous explique comment ce petit malin combine IA et rigueur – et pourquoi il pourrait bien révolutionner votre prochain chatbot d’entreprise.
Le RAG chatbot, ou l’art de donner une mémoire à l’IA
Imaginez un chatbot classique face à cette question : « Qui a gagné la Coupe du Monde 2022 ? ». Alors que le monde entier connaît la réponse (l’Argentine), notre IA, figée dans ses données d’entraînement de 2021, répond avec aplomb : « La France a remporté la dernière Coupe du Monde en 2018 ». Classique. Le LLM, c’est ce génie un peu désuet qui a tout appris par cœur, mais qui rate le train de l’actualité.
Le RAG, c’est donner à un LLM un accès à internet et une bibliothèque, mais avec un bibliothécaire super rapide qui lui trouve la bonne page avant qu’il ne se mette à inventer.
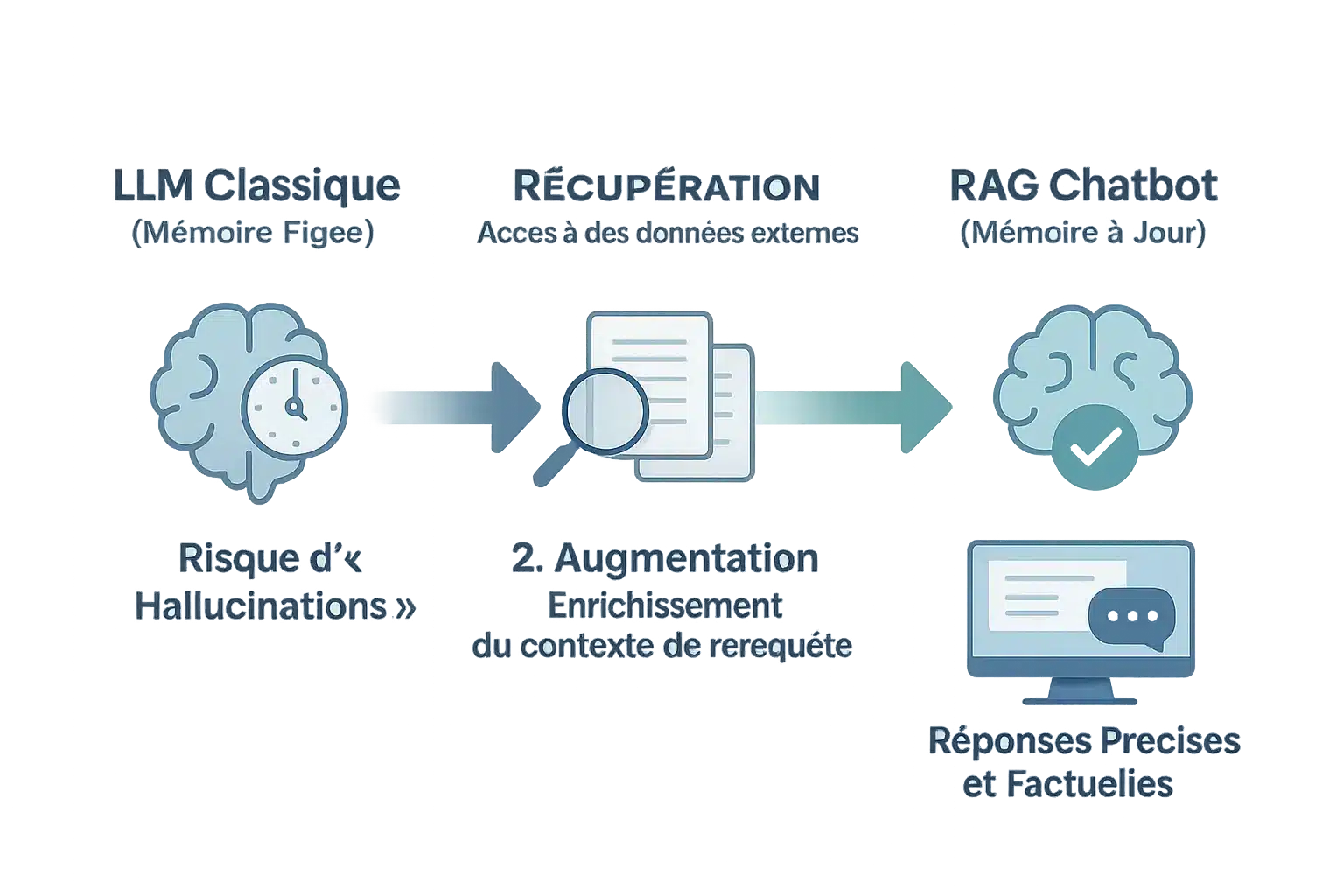
Le RAG chatbot (Retrieval-Augmented Generation) résout ce problème. C’est l’équivalent d’un étudiant brillant qui consulte les dernières études avant de répondre. Le processus ? Trois étapes : Récupération, Augmentation, Génération.
Récupération : Le chatbot fouille une base externe (sites web, documents) pour trouver des données fraîches. Augmentation : La question de l’utilisateur est enrichie avec ces infos, comme un sandwich jambon-fromage… mais en informatique. Génération : Le LLM utilise ce contexte pour une réponse cohérente, sans délirer sur des faits inexacts.
Pourquoi c’est utile ? Cela réduit les hallucinations (réponses inventées) et cite ses sources. Un chatbot normal, c’est un professeur qui n’a pas ouvert un livre depuis 2015. Le RAG, c’est le même prof avec Google dans la poche.
Mais attention : si les sources externes sont douteuses, la réponse le sera aussi. C’est un peu comme demander à un ami malin de conseiller un film, sauf que son avis vient d’un site rempli de critiques bidon. L’IA reste un miroir de ses sources, mais dans 90 % des cas, elle évite de passer pour un ignare face à votre patron.
En résumé, le RAG chatbot, c’est l’alliance du cerveau du LLM et du réflexe Google. Une combo gagnante pour éviter les boulettes numériques… et garder votre crédibilité intacte.
Sous le capot d’un RAG chatbot : le pipeline décortiqué
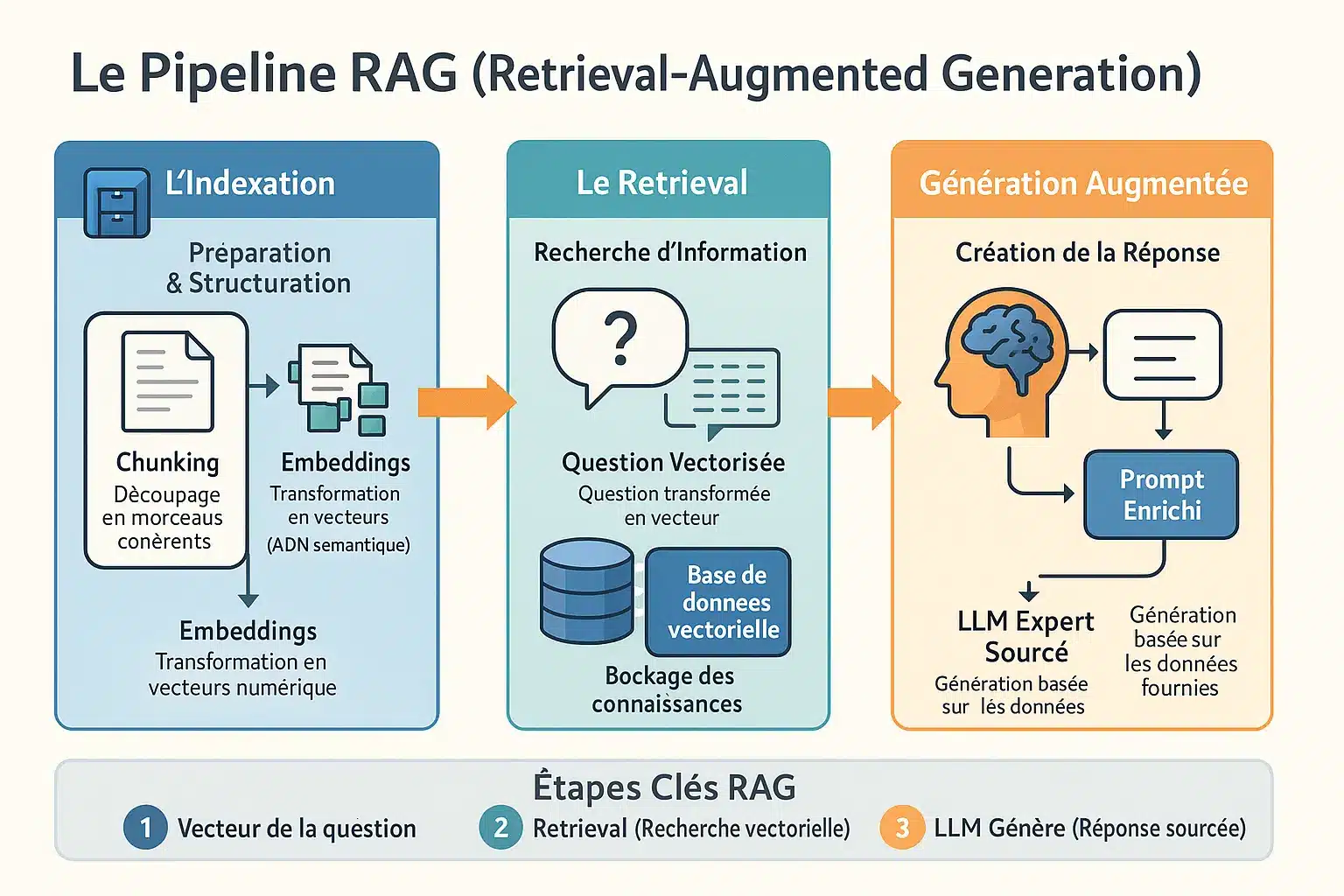
L’indexation : transformer le chaos des données en savoir structuré
Avant toute interaction, le RAG prépare sa propre “cuisine” en découpant des données (PDF, web, etc.) en morceaux digestibles. Ce chunking suit des méthodes variées : taille fixe (comme un couteau de boulanger tranchant un pain de mie), structure (suivant les paragraphes ou titres) ou sémantique (regroupant des idées liées). Chaque chunk devient une fiche de savoir, transformée en code via des embeddings.
Les embeddings sont des coordonnées dans un espace sémantique. Des sujets proches (comme “chat” et “félin”) cohabitent dans ce monde virtuel, tandis que des concepts éloignés (comme “voiture” et “bateau”) occupent des zones distinctes. C’est un peu comme un GPS qui regroupe les restaurants italiens dans un même quartier. Par exemple, si vous cherchez “pizzeria”, le système comprendra aussi “trattoria” ou “ristorante” grâce à leur proximité vectorielle.
Le retrieval : la pêche miraculeuse de l’information pertinente
La requête utilisateur devient un vecteur dans cet espace abstrait. La recherche par similarité vectorielle compare ce vecteur à des milliers de chunks. Trois méthodes dominent : distance euclidienne (mesure d’écart), similarité cosinus (direction), et produit scalaire (direction et intensité). C’est comme choisir entre carte routière, compas ou odomètre pour retrouver son chemin. Imaginez un système qui comprend que “voiture électrique” est plus proche de “véhicule écologique” que de “tracteur diesel”.
La base de données vectorielle, avec des outils comme Faiss ou Milvus, agit comme un bibliothécaire ultra-rapide. Elle repère les 3-4 morceaux parfaits dans des millions, en un clin d’œil. Sans elle, le système serait perdu comme un humain cherchant une aiguille dans une botte de foin. Ces outils utilisent des algorithmes spécialisés (HNSW, LSH) pour éviter de parcourir toute la bibliothèque à chaque requête.
La génération augmentée : quand le LLM devient un expert sourcé
L’IA devient un stagiaire consciencieux : elle reçoit votre question + documents pertinents, comme des fiches de révision avant un examen. La réponse suit trois étapes :
- Transformation de la question en vecteur
- Recherche des documents via similarité
- Génération ancrée dans ces sources
Cette approche éclate les limites des chatbots classiques. Le RAG devient un expert temporaire capable de citer des données récentes. C’est comme un assistant qui lit 100 livres en une seconde avant de répondre à une question sur les dinosaures ou la physique quantique. Par exemple, si vous demandez “Quelle est la taille du plus gros dinosaure ?”, le système récupère des articles scientifiques récents et génère une réponse précise avec sources.
Mais ce super-pouvoir a un prix : les réponses dépendent de la qualité des sources externes. Chaque requête coûte plus cher qu’un chatbot basique, comme un cuisinier vérifiant 10 recettes en temps réel pour offrir la meilleure recette de gâteau au chocolat. Le RAG reste néanmoins plus fiable qu’un modèle se basant sur sa seule mémoire d’entraînement, souvent datée.
Les super-pouvoirs du RAG : pourquoi c’est une petite révolution
Adieu les hallucinations : des réponses basées sur des faits
Imaginez un chatbot qui ne vous sort plus des bobards avec un sourire charmeur. Grâce au RAG, le modèle ne se contente plus d’inventer des réponses à partir de souvenirs lointains. Il fouille dans ses fiches (des documents externes) avant de parler. Résultat : 15 à 20 % d’hallucinations en moins dans les domaines dynamiques comme la finance ou la santé. C’est comme passer d’un raconteur d’histoires à un journaliste fact-checké. Par exemple, un chatbot médical équipé de RAG pourra citer des symptômes vérifiés dans des bases de données actualisées, plutôt que d’inventer des traitements fantaisistes.
Des connaissances toujours à jour (ou presque)
Plus besoin de réentraîner tout le modèle pour un détail. Un chatbot RAG se branche sur des données en temps réel (ou presque) à moindre coût. Mettre à jour sa base externe coûte 20 fois moins cher par token que de refaire un entraînement complet. Un peu comme avoir une mémoire externe qu’on peut actualiser sans subir une opération cérébrale. Dans le secteur bancaire, un chatbot pourrait intégrer en direct les variations des taux de change, contrairement à un modèle classique figé à la date de son entraînement. Cette flexibilité ouvre même aux PME des possibilités autrefois réservées aux mastodontes tech.
La transparence en prime : le chatbot cite ses sources
Quand un RAG répond, il sait exactement quels documents il a piochés. Et il vous le dit ! Une révolution pour les secteurs exigeants (juridique, médical). Vous vérifiez les sources, comme un prof qui relit vos références bibliographiques. C’est un peu comme si votre assistant IA devenait votre petit camarade de bibliothèque, toujours prêt à pointer la page exacte d’un manuel. Et si vous voulez aller plus loin pour humaniser ces réponses robotiques tout en garantissant leur fiabilité, voici une méthode efficace pour humaniser les réponses de l’IA.
“Avec le RAG, le chatbot ne se contente plus de ‘penser’ savoir la réponse, il va la ‘vérifier’ dans ses notes avant de parler. Une révolution pour la confiance et la fiabilité de l’IA.”
- Réduction drastique des hallucinations.
- Accès à des données récentes et spécifiques.
- Transparence totale grâce au sourçage des réponses.
- Personnalisation plus économique et rapide que le fine-tuning.
RAG vs fine-tuning : le match pour personnaliser votre IA
Deux gladiateurs s’affrontent dans l’arène de l’intelligence artificielle : le RAG, surnommé « l’archiviste fouineur », et le fine-tuning, alias « le sculpteur de neurones ». L’un maîtrise la recherche instantanée, l’autre la réécriture cérébrale. Qui mérite le titre de champion ?
Présentation des combattants
Le RAG agit comme un étudiant malin : plutôt que de tout mémoriser, il puise en temps réel dans des sources fiables. Un chatbot RAG cite vos procédures internes ou les cours boursiers à la seconde, sans sortir de sa zone de confort.
Le fine-tuning ressemble à un musicien répétant une partition. Entraîné sur des données ciblées, il adopte un ton juridique ou un style d’écriture spécifique. Son savoir est profond, mais figé.
Quand choisir qui ?
Pour des données évolutives (cours de crypto, réglementations), le RAG est idéal. Besoin d’un chatbot citant votre manuel mis à jour ? RAG s’en sortira.
Envie d’un assistant rédigeant des contrats en jargon juridique ou en style pompeux ? Le fine-tuning sculptera son ton. Attention : si les règles changent, il faut le réadapter.
Tableau comparatif : RAG vs. Fine-Tuning
| Critère | Approche RAG | Approche Fine-Tuning |
|---|---|---|
| Objectif principal | Ajouter des connaissances externes. | Adapter le style ou le comportement du modèle. |
| Mise à jour des connaissances | Simple via la base de données. | Complexe, nécessite un réentraînement. |
| Risque d’hallucination | Faible, basé sur des documents. | Modéré, peut inventer des faits. |
| Transparence | Élevée, cite ses sources. | Nulle, réponses opaques. |
| Coût | Relativement bas. | Élevé, exige des ressources. |
Choisir entre ces méthodes, c’est comme opter entre un livre de recettes à feuilleter ou un chef l’ayant mémorisé. Pour un aperçu des plateformes, ce comparatif de chatbots IA pourrait vous guider.
La synergie inattendue
Pas obligé de choisir ! RAG et fine-tuning forment une équipe redoutable. Un modèle fine-tuné pour le ton d’une marque peut utiliser le RAG pour glisser des données à jour. Le RAG fournit les faits, le fine-tuning sublime le style. Cette alliance réduit les faiblesses de chaque méthode tout en multipliant les forces : données fraîches et style ciblé, en harmonie. Un duo improbable, mais efficace.
Mettre les mains dans le cambouis : les outils pour construire un RAG
Un RAG, c’est comme une cuisine high-tech : des ingrédients précis, des outils spécialisés, et un chef (vous) qui orchestre le tout. Pas besoin de coder, juste de comprendre les bases.
Les chefs d’orchestre : LangChain et LlamaIndex
LangChain et LlamaIndex sont les deux stars de l’assemblage. LangChain, c’est l’organisé : il lie les étapes (récupération, traitement, génération) avec des outils clés en main. LlamaIndex, lui, est le perfectionniste : il transforme vos données en index exploitables.
Leur super-pouvoir ? Automatiser le gros du boulot : découpes de textes, stockage, et interactions avec les modèles de langage. Un peu comme un kit de montage facile à suivre.
Les 4 fantastiques pour votre premier RAG
- Un framework d’orchestration comme LangChain pour lier le tout.
- Un modèle d’embedding pour transformer le texte en vecteurs.
- Une base de données vectorielle pour stocker et retrouver ces vecteurs.
- Un grand modèle de langage (LLM) pour générer la réponse finale.
Les composants clés
Les modèles d’embedding traduisent le texte en nombres, permettant des comparaisons sémantiques. Des outils comme Sentence-Transformers (gratuit) ou les APIs d’OpenAI (payantes) font l’affaire. À vous de choisir entre budget serré et performance brute.
Les bases vectorielles, c’est la mémoire du système. Chroma est parfait pour les prototypes (gratuit, mais limité), Pinecone pour la production (rapide, mais coûteux), Milvus pour les gros projets (puissant, mais complexe). Le choix du LLM est crucial, et oui, on peut même tester ChatGPT gratuitement.
Le match des bases vectorielles
Chroma, c’est le petit frère sympa : gratuit, rapide, mais réservé aux projets légers. Pinecone, la star du speed, mais son prix pique. Milvus, la brute pour l’entreprise, mais lourde à configurer. Weaviate, lui, mixe recherche vectorielle et mots-clés, idéal pour les hybridations malines.
En résumé : Chroma pour démarrer, Pinecone pour la performance, Milvus pour les mastodontes. Et si vous voulez briller, Weaviate combine deux mondes en un.
L’avenir du RAG : vers des systèmes encore plus malins
Les stratégies de recherche avancées : au-delà de la simple similarité
Le “Retrieval” classique, c’est comme un ami cherchant vos clés en se basant sur leur couleur. Bonne idée… jusqu’à ce qu’elles soient cachées sous une serviette. La recherche hybride combine deux approches : mots-clés (TF-IDF, BM25) pour les détails précis, et recherche vectorielle pour capter le contexte. Sur Stack Overflow, ce duo repère à la fois le code exact et les solutions contextuelles. Résultat ? Une efficacité accrue sur des requêtes complexes.
Et si ça ne suffisait pas ? Le re-ranking affine le tri. Un modèle secondaire re-classe les résultats pour ne garder que le top avant de l’envoyer au LLM. Comme un tri dans une pile de documents : place à la précision, zéro gaspillage. Ce modèle utilise souvent un cross-encodeur, analysant la requête et le document ensemble, évitant les pertes d’information des méthodes classiques. Oui, c’est plus lent, mais la précision en vaut la chandelle.
L’ère des systèmes multi-agents : une équipe d’IA pour une seule réponse
Les systèmes multi-agents transforment votre chatbot en une équipe de spécialistes. Le “routeur” analyse la question, le “chercheur” explore bases de données et forums, le “synthétiseur” compile les données, et le “vérificateur” élimine les erreurs. Comme une équipe de heist bien rodée.
Exemple : une requête sur un bug de code. Le chercheur fouille forums techniques et base vectorielle. Le synthétiseur compile les solutions, le vérificateur écarte les méthodes obsolètes. Résultat ? Une réponse claire, vérifiée, sans approximations. Ces systèmes évitent les hallucinations et renforcent la robustesse. Pas mal pour une bande d’algorithmes, non ?
Alors, le RAG chatbot est-il la solution miracle pour votre projet ?
Disons-le : si un RAG chatbot pouvait être un magicien, il éviterait les tours de passe-passe des données. En combinant LLM et récupération externe, il transforme un modèle bavard en assistant précis, comme passer d’un conteur à un expert.
Les LLMs, même les meilleurs (comme Gemini-2.0-Flash à 0,7% d’hallucination), ne sont pas infaillibles. Le RAG agit comme un coach : il leur rappelle de vérifier leurs sources, évitant les erreurs du genre « La Tour Eiffel est bleue ».
Mais ce n’est pas une baguette magique. Comme un plat, la qualité dépend des ingrédients. Un chunking bancal ou des sources désordonnées donnent un résultat raté. Avec des données pertinentes, le RAG devient l’allié d’un chatbot sérieux.
Pourquoi s’en priver ? Les systèmes RAG sont devenus la norme pour les entreprises voulant éviter que leur chatbot réinvente l’histoire. Réduction des hallucinations, personnalisation : c’est une nécessité. Qui répondrait à un client : « Selon mes hallucinations, votre facture est payée » ?
Le futur brille. Avec des architectures hybrides, le RAG prépare les assistants IA à être les Sherlock Holmes de la donnée. Pas de magie : juste un équilibre entre technologie et rigueur.
Le RAG chatbot, ce n’est pas un magicien, mais un organisateur de génie : il transforme le chaos des données en réponses sourcées. Adieu aux hallucinations d’un LLM esseulé, bonjour à l’IA experte… si vos données sont impeccables. Après tout, même le meilleur bibliothécaire du monde ne peut rien contre des livres mal écrits ! 📚✨
FAQ
Quel est le secret derrière l’acronyme RAG ?
Le RAG, c’est l’histoire d’un chatbot qui a enfin décidé de ne plus vivre dans le passé. Derrière ce mot qui fait penser à un cri de frustration se cache en réalité Retrieval-Augmented Generation, soit « Génération Augmentée par la Récupération » en bon français. Le concept est simple : au lieu de se reposer uniquement sur ses connaissances figées (comme ce collègue qui cite toujours les mêmes anecdotes de vacances de 2003), le chatbot va chercher en temps réel l’info la plus fraîche pour répondre. Imaginez un élève qui, au lieu d’apprendre tout un manuel par cœur, a le droit d’aller chercher les bonnes réponses dans la bibliothèque pendant l’examen – mais en beaucoup plus légal.
Un RAG, c’est juste un chatbot qui a du vague à l’âme ?
Pas du tout ! Un RAG (Retrieval-Augmented Generation) est plutôt un chatbot sur-qualifié. Il combine deux super-pouvoirs : d’abord, il explore des bases de données externes pour trouver les informations les plus pertinentes (son retrieval), puis il génère une réponse hyper-ciblée en intégrant ces données (sa generation). C’est comme un critique cinéma qui ne se contente plus de ses souvenirs flous, mais qui va vérifier les détails du film, les dernières interviews du réalisateur, et les critiques récentes avant de balancer son avis. Résultat : un chatbot qui sait qui a gagné la dernière Ligue des Champions, et même ce que vous avez mangé hier si vous le lui avez raconté.
Un agent IA RAG, c’est le génie paresseux de la Silicon Valley ?
En quelque sorte ! Un agent IA RAG est ce collègue ultra-productif qui ne fait jamais rien directement. Il commence par envoyer un stagiaire chercher les bonnes informations (son retrieval), puis il lit ce que le stagiaire lui ramène et rédige une réponse parfaite avec un minimum d’effort (sa generation). Concrètement, c’est un LLM (ce type qui sait tout mais qui oublie tout) équipé d’un assistant zélé qui lui fournit les données clés en temps réel. Résultat : un système qui ne raconte pas n’importe quoi, qui cite ses sources, et qui peut expliquer pourquoi il a pris telle ou telle décision. En gros, l’IA la plus crédible depuis qu’on a enfin expliqué aux chatbots qu’ils ne sont pas là pour improviser un one-man-show.
RAG vs GPT : la guerre des acronymes ou des approches ?
C’est surtout la différence entre un artiste et son assistant. GPT (Generative Pre-trained Transformer) est le peintre : il crée des réponses à partir de ce qu’il a appris pendant son entraînement. Mais comme il a tendance à confondre l’art et le plagiat, il peut se retrouver à chanter Imagine de John Lennon en croyant que c’est du Justin Bieber. Le RAG, lui, c’est le manager du peintre : il vérifie d’abord les faits dans une bibliothèque d’œuvres récentes, puis guide le GPT pour qu’il reste dans les clous. En résumé, GPT c’est l’artiste fou, RAG le producteur pragmatique. Ensemble, ils font un album qui ne sera peut-être pas iconique, mais au moins légal.
Pourquoi diable utiliser un RAG ?
Parce que personne n’a envie qu’un chatbot vous réponde « Ah bah je crois que la Terre est plate d’après mes dernières données de 1492 ». Le RAG est né d’une idée simple : plutôt que de réentraîner un modèle entier (opération coûteuse et lente), on peut simplement lui coller une mémoire externe. Comme coller un post-it sur son frigo pour ne plus oublier qu’on est allergique aux fruits de mer. Cela permet de réduire les hallucinations, d’être à jour sur les tendances TikTok (ou les lois fiscales, selon votre usage), et surtout de citer ses sources. Bref, c’est le moyen le plus économique pour transformer un bavard invétéré en expert fiable. Comme offrir à votre oncle qui raconte toujours la même blague sur les Belges un livre de punchlines actualisées.
RAG vs IA classique : la fin du copier-coller mental ?
Imaginez deux candidats à Koh-Lanta : l’IA classique est ce joueur qui a mémorisé la carte de l’île par cœur, mais qui panique quand un volcan entre en éruption. Le RAG, lui, est celui qui a une montre connectée avec GPS et prévisions météo en temps réel. L’IA classique (comme GPT) génère ses réponses à partir de ce qu’elle a appris pendant son entraînement, ce qui peut mener à des dérapages dignes d’un élève qui révise mal son bac. Le RAG, lui, consulte d’abord des sources externes, ce qui réduit les hallucinations et garantit des réponses sourcées. En gros, c’est la différence entre un prof qui fait cours par cœur et un autre qui vérifie ses notes avant chaque diapositive – le second est moins risqué pour un exposé sur les dernières découvertes scientifiques.
La RAG, c’est juste un truc de geek ou une révolution ?
Une révolution avec un petit gilet pare-balles technologique. Le RAG (Retrieval-Augmented Generation) est un concept qui permet à un LLM (Large Language Model) de sortir de sa bulle d’informations figées. Il fonctionne en trois étapes : d’abord, il récupère les données les plus pertinentes depuis des sources externes (votre base de données, le web, etc.), puis il « augmente » ces données avec la question de l’utilisateur, enfin il génère une réponse basée sur ce cocktail d’informations. C’est comme si votre chatbot, au lieu de se fier uniquement à sa mémoire (souvent aussi fraîche qu’un pain de mie oublié), avait un assistant qui lui glisse discrètement les bonnes réponses en temps réel. Résultat : des réponses plus précises, des hallucinations réduites, et surtout une IA capable de citer ses sources – un détail qui change tout quand on parle de droit, de santé ou de la dernière saison de votre série préférée.
Les 4 types d’IA : une classification ou un défi pour geek de la catégorisation ?
Classer les IA, c’est un peu comme ranger ses chaussettes : personne n’a la même méthode, mais tout le monde finit par y arriver. Selon les dernières classifications (enfin, celles d’avant-hier, car le domaine évolue plus vite que votre forfait internet), on distingue :
– Les réactives : simples et rapides, comme ce collègue qui répond « Ouais, cool » à toutes vos questions.
– Les proactives : celles qui anticipent vos besoins, genre Google qui vous propose des recettes de gâteau alors que vous avez juste cherché « four chaud ».
– Les adaptatives : comme votre chat qui comprend quand vous avez eu une mauvaise journée et vous laisse tranquille.
– Les rationnelles : obsédées par la logique, elles vous expliquent pourquoi votre relation amoureuse est vouée à l’échec avec des graphiques Excel.
Le RAG, lui, joue un peu dans toutes les catégories puisqu’il peut être réactif, proactif, adapté à votre contexte, et rationnel dans ses réponses – un peu comme un chatbot polyvalent qui ne se prend pas pour Dieu.



